Сканируем интернет со Spidy
Как и обещал, продолжение наших опытов по сканированию интернетов.
И так, мы продолжаем наш эксперимент со сканированием интернета. В предыдущей статье мы рассмотрели самый простой вариант того, как нам просканировать интернет на открытые FTP с анонимным доступом. В этот раз мы немного изменим подход, у нас будет больше опций посика плохо сконфигурированных сервисов, а так же у нас будет утилита, которая упрощает процесс и в которую можно легко дописать дополнительные типы проверок.
Как показывает практика, чтобы взломать ту или иную систему, совершенно не обязательно обладать каким-то определенным набором эксплойтов, а в наше время и даже навыками. Почему так получается? Ответ прост — человеческий фактор.
Очень часто, системы которые доступны из интернета настраивают не правильно, используют стандартные или простые пароли, забывают обновлять, как раз этим мы и сможем воспользоваться. Для опытов я рекомендовал бы поднимать свою тестовую среду, чтобы не нарушать законы.
Данная статья написана исключительно в образовательных целях.
Что мы будем использовать
Для очередного эксперимента нам понадобится следующий стек:
- Python (лучше версии 2.7)
- PHP — на php будет работать наша панель доступа к базе данных
- MySQL — используется для хранения результатов
- Debian — то, на чем все будет крутиться
- ZMap — Отвечает за создание базы IP адресов с определенными открытыми портами
- Proxychains — в данном случае будет использоваться в качестве примера, как выполнять сканирование анонимно
Для этой статьи я разработал простенький, но в то же время удобный сканер «Spidy» на python. В перспективе, если он кого-то устроит, его можно довольно просто дорабатывать добавляя разного рода проверки и так же, можно будет добавить многопоточность если кому-то это нужно.
Для упрощения работы с результатами, отдельно на php была написана панелька. В веб панели можно будет смотреть общую статистику и так же выполнять более-менее удобный поиск по результатам.
Создание и настройка тестовой среды
Для начала, как и прошлый раз — нам надо получить VPS сервер. Бесплатный VPS сервер на фактически 1-2 месяца использования можно взять пройдя по ссылке.
Базовую настройку сервера можно выполнить при помощи серии статей о настройке VPS сервера которую я писал ранее. При настройке сервера, так же учитывайте стек технологий которые мы будем использовать и если чего-то не хватает в статье про настройку сервера, попытайтесь разобраться с этим самостоятельно. Про то, как установить zmap и возможные проблемы в процессе установки, мы не так давно тоже разбирали. Так же, я бы рекомендовал выполнить установку proxychains, потому как оно используется в скрипте на этапе формирования базы, но его можно и вырезать если не надо и опыты будут проводиться локально.
После того, как вы все настроили, вам понадобится инструмент, скачать все, что нужно можно по ссылке ниже. В архив входит:
- Скрипт сканирования Spidy
- Веб панель для работы с результатами
https://github.com/sm0k3net/spidy/archive/master.zip
Приступим к тестам
Первым делом, качаем и распаковываем наш инструментарий. Скачать можно на компьютер пройдя по ссылке и перебросить к себе на сервер с помощью FTP или SFTP (для Windows — WinSCP).
Либо, скачать и распаковать можно прямиком на сервер:
wget https://github.com/sm0k3net/spidy/archive/master.zip && unzip master.zip cd master && chmod +x spidy.py
Работать нам надо будет под рутом как минимум на этапе выполнения сбора информации о хостах и портах в нашу БД. Эту часть можно выполнить самому ну или же заставить скрипт крутиться по расписанию самостоятельно с помощью крона.
Открываем скрипт и в него записываем данные аутентификации в БД, параметры находятся с 19 по 22 строку.
Нам это надо для того, чтобы:
- Создать таблицу для сохранения результатов
- На основе этих результатов будет работать наш сканер
- В БД будут записываться финальные результаты выполненных проверок
На втором шаге, после того как мы все скачали и выставили права на выполнение, нам надо инициализировать БД, а так же создать простенький словарь для выполнения брутфорса. Для этого выполняем следующую команду:
./spidy.py db_init
После того, как мы инициализировали базу данных, нам надо обзавестись списком пула IP адресов, по которому мы отправим Spidy собирать для нас нужную информацию. Список пулов можно получить абсолютно по любой стране, просто укажите то, что вас интересует во втором ключе при запуске скрипта. Для примера мы попросим скачать для нас список из зоны RU. Для получения заветного списка, надо выполнить следующую команду:
./spidy.py ip_list ru
Наш файлик с перечнем IP диапазонов будет называться «ip_list_ru.txt» и лежать рядом с нашим скриптом.
Ну вот, у нас есть уже специально подготовленная таблица в БД для записи результатов и список IP адресов, которые мы будем проверять, приступим к следующему шагу.
На следующем этапе, нам надо задать для Spidy параметры сканирования и откуда брать данные. Давайте попробуем опять вернуться к теме анонимных ФТП:
./spidy.py scan ip_list_ru.txt 21
Мы попросили spidy выполнить сканирование по списку адресов из нашего файлика, а искать он будет все хосты с открытым 21 портом (FTP).
Ваша база данных будет автоматически наполняться списком хостов, можно за это время сделать чай и развернуть нашу веб панель. Про первое я думаю, рассказывать не стоит, а вот про вторую часть давайте я объясню.
В архиве, который вы скачали, будет папочка «web_panel», содержимое этой папки вам надо будет перенести к себе на сервер и положить в папку веб-сервера (сайта) который смотрит наружу (как при создании сайта).
Далее, открываем файлик db.php и в нем указываем данные аутентификации к вашей БД, данные надо указывать те же, что использовали для Spidy.
 Хорошо, с настройкой панели мы закончили. Если все было сделано правильно, то при переходе на страничку «index.php» мы увидим интерфейс нашей панельки. Сразу хочу отметить, что панелька очень простая, потому как интерфейс я думаю, сможет каждый сам сделать под себя, при желании, а для статьи писать какие-то крутые интерфейсы — лишняя трата времени.
Хорошо, с настройкой панели мы закончили. Если все было сделано правильно, то при переходе на страничку «index.php» мы увидим интерфейс нашей панельки. Сразу хочу отметить, что панелька очень простая, потому как интерфейс я думаю, сможет каждый сам сделать под себя, при желании, а для статьи писать какие-то крутые интерфейсы — лишняя трата времени.
Пока мы пили чай и настраивали нашу веб-панель, сканер уже должен был закончить свою работу и собрать для нас внушительную базу хостов с открытым FTP сервисом (порт 21).
Следующий шаг какой делать, решать уже вам. Вы можете сразу набить вашу базу данных нужными хостами с нужными портами и работать уже сразу по нескольким типам уязвимостей (через cron, screen и т.д.). В данный момент, скрипт может проверять следующие типы ошибок конфигурации:
- FTP с анонимным доступом
- SSH с отсутствующим или слабым паролем (данные для брутфорса находятся в файлике «words.txt», который был сгенерирован в процессе инициализации БД)
- Выполняет поиск баз данных MongoDB, в которых не настроена авторизация
Скрипт не сохраняет в результаты какой-то критичной информации, так как мы приследуем образовательные цели, по этому — в результатах БД можно будет увидеть либо «fail», либо «success» результаты авторизации/получения баннеров (столбец «banner» в БД).
У нас есть БД, панель и уже готовый массив хостов с открытым FTP, которые мы будем проверять. Следующим шагом будет выполнение тех самых проверок, для этого скрипт надо запустить со следующими ключами:
./spidy.py check ftp
Эта часть работы скрипта из-за отсутствия многопоточности и наличия хоть и небольшого таймаута, будет выполняться гораздо дольше, но в целом — достаточно быстро. Тут уже все будет зависить только от ваших мощностей и списка хостов.
Скрипт будет выполнять проверку по списку хостов из базы данных, которые были туда добавлены с 21 портом (столбец «port» в БД).
По окончании проверки (или если вы ее прервете), мы получите уже готовые результаты. Чтоб с этими результатами было проще работать, перейдем в нашу панельку. На главной странице можно увидеть небольшую общую статистику:
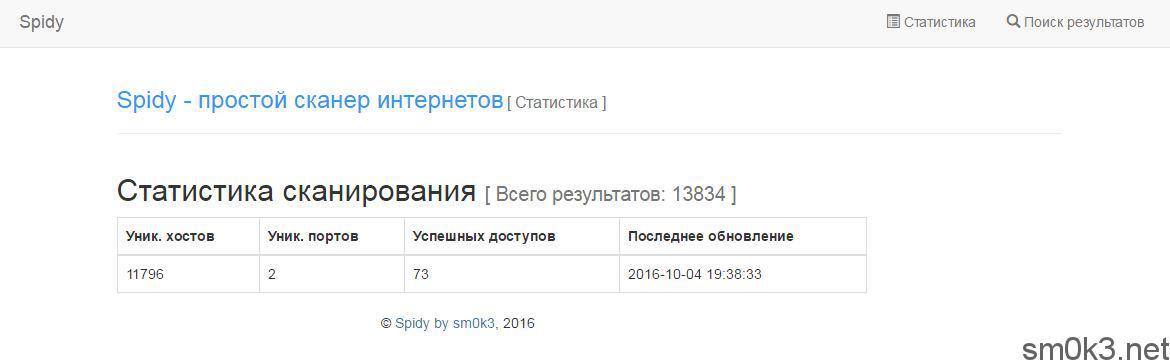
Статистика у нас показывает общее количество записей в БД, количество уникальных хостов, количество уникальных портов на которые мы сканировали, количество успешных проверок (если доступ был получен) и дату последнего добавления/обновления результатов.
Но, это еще не все, кроме статистики — мы так же можем и оперирывать нашими результатами, для этого надо перейти в «Поиск результатов»:
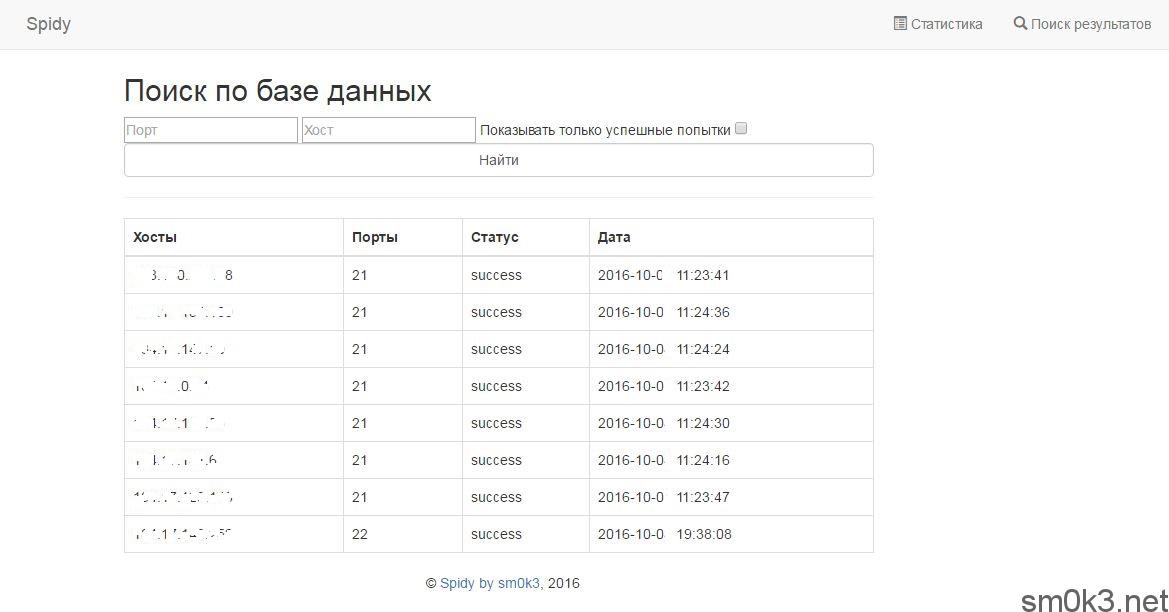
В поиске у нас доступные следующие параметры:
- Поиск по порту
- Поиск по хосту (или всей базе)
- Фильтрация результатов по успешности (отсеивает все «fail»)
Можете попробовать указать порт 21 и посмотреть все результаты (весь список). Либо, если вы выполняли сканирование по нескольким типам сервисов (портов), то поиск можно упростить: в поле порт мы ничего не пишем, а в поле «Хост» мы пишем лишь «%» (без кавычек) и ставим галочку «Показывать только успешные попытки». Такой тип поиска выдаст вам все успешные результаты проверок по всем портам и хостам, все результаты с «fail» — выводиться не будут.
В случае, если вы хотите достать список хостов из БД в удобном для парсинга формате, то Spidy вам может и в этом помочь, для этого надо запустить его со следующими ключами:
./spidy.py export 21 test.txt
Все результаты сканирования по 21 порту будут экспортированы в файлик «text.txt» рядом со скриптом.

Сам Spidy работает с классами и внести какие-то правки/дополнения в него — очень просто. Для более эффективной работы в него еще по хорошему можно было бы внести несколько типов проверок: mysql, heartbleed, поиск бекапов, сервер статусы и т.д., а так же неплохо было бы добавить многопоточность. За исключением процесса формирования массива адресов с открытыми портами — можно было бы реализовать управление через веб-панель, немного расширить ее функционал.
Использовать Spidy можно как руками, выполняя все операции самостоятельно, так и при помощи крона запускать его с нужными ключами по расписанию и только заходить в панельку для проверки результатов.
Может быть интересно:



